













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


SparkMllib数值型特征基本处理方法介绍[大数据培训]
更新时间:2019年09月18日17时20分 来源:传智播客 浏览次数:
在SparkMllib中主要分为特征抽取、特征转化、特征选择,特别是在特征转化方面是从一个DataFrame转化为另外一个DataFrame,在数值型数据处理的时候我们对机器学习数据集中的样本和特征部分进行单独的处理,这里就涉及对样本的正则化操作和数值型特征的归一化和标准化的方法,今天就带大家理解这一部分的思考和认识。
1.数据归一化
什么是数据的归一化?
答:数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
为什么对数据归一化处理?
我们在对数据进行分析的时候,往往会遇到单个数据的各个维度量纲不同的情况,比如对房子进行价格预测的线性回归问题中,我们假设房子面积(平方米)、年代(年)和几居室(个)三个因素影响房价,其中一个房子的信息如下:
面积(S):150 平方米
年代(Y):5 年
这样各个因素就会因为量纲的问题对模型有着大小不同的影响,但是这种大小不同的影响并非反应问题的本质。
为了解决这个问题,我们将所有的数据都用归一化处理至同一区间内。

2.数据标准化
什么是标准化(StandardScaler)?
训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。标准化之后,数据的范围并不一定是0-1之间,数据不一定是标准正态分布,因为标准化之后数据的分布并不会改变,如果数据本身是正态分布,那进行标准化之后就是标准正态分布。
(1)归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row样本数据)进行缩放。对行进行缩放是毫无意义的。比如三列特征:身高、体重、血压。每一条样本(row)就是三个这样的值,对这个row无论是进行标准化还是归一化都是无意义的,因为你不能将身高、体重和血压混到一起去。
(2)标准化/归一化的好处
提升模型精度:基于距离的算法,例如Kmeans、KNN等,各个特征的量纲直接决定了模型的预测结果。举一个简单的例子,在KNN中,我们需要计算待分类点与所有实例点的距离。假设每个实例点(instance)由n个features构成。如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。对于PCA,如果没有对数据进行标准化,部分特征的所占的信息可能会虚高。
提升收敛速度:例如,对于linear model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。对于SVM标准化之后梯度下降的速度加快。
3.标准化和归一化的对比分析
(1)标准化/归一化的对比分析
首先明确,在机器学习中,标准化是更常用的手段。
MinMaxScaler对异常值非常敏感。例如,比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。
当数据需要被压缩至一个固定的区间时,我们使用MinMaxScaler.
(2)在逻辑回归中需要使用标准化么?
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。为什么呢?因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。
举一例来说,我们预测身高,体重用kg衡量时,训练出的模型是: 身高 = x*体重+y*父母身高,X是我们训练出来的参数。当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。在上面两种情况下,都用L1正则的话,显然当使用kg作为单位时,显然对模型的训练影响是不同的。
再举一例来说,假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1会对那些级别比较大的参数正则化程度高,那些小的参数都被忽略了。
就算不做正则化处理,建模前先对数据进行标准化处理也是有好处的。进行标准化后,我们得出的参数值的大小可以反应出不同特征对label的贡献度,使参数具有可解释性。
这里注意一点:有些需要保持数据的原始量纲的情况下,不能对数据进行标准化或者归一化处理。例如,制作评分卡
而如何理解正则化方法呢?
我们在训练模型时,要最小化损失函数,这样很有可能出现过拟合的问题(参数过多,模型过于复杂),所以我么在损失函数后面加上正则化约束项,转而求约束函数和正则化项之和的最小值。
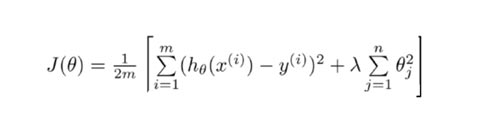
4. SparkMllib代码实战
0 数据准备
// 原始数据
+---+---------------------+
| id| features|
+---+---------------------+
| 0|[1.0,0.5,-1.0]|
| 1| [2.0,1.0,1.0]|
| 2|[4.0,10.0,2.0]|
+---+---------------------+
代码如下:
import org.apache.spark.ml.linalg.Vectors
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.5, -1.0)),
(1, Vectors.dense(2.0, 1.0, 1.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)).toDF("id", "features")
dataFrame.show
4.1 Normalizer
Normalizer的作用范围是每一行,使每一个行向量的范数变换为一个单位范数
作用对象:行
方法公式:
L1范数是指向量中各个元素绝对值之和
colX/(|col1|+|col2|...+|coln|)
L2范数是指向量各元素的平方和然后求平方根
colX/(|col1^2|+|col2^2|...+|coln^2|)^(1/2)
Ln无穷阶范数最终趋近于绝对值最大的元素(x趋近于无穷)
colX/(|col1^x|+|col2^x|...+|coln^x|)^(1/x)
max(|col1|,|col2|...|coln|)
import org.apache.spark.ml.feature.Normalizer
// 正则化每个向量到1阶范数
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
println("Normalized using L^1 norm")
l1NormData.show()
// 将每一行的规整为1阶范数为1的向量,1阶范数即所有值绝对值之和。
+---+--------------+------------------+
| id| features| normFeatures|
+---+--------------+------------------+
| 0|[1.0,0.5,-1.0]| [0.4,0.2,-0.4]|
| 1| [2.0,1.0,1.0]| [0.5,0.25,0.25]|
| 2|[4.0,10.0,2.0]|[0.25,0.625,0.125]|
+---+--------------+------------------+
// 正则化每个向量到无穷阶范数
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
println("Normalized using L^inf norm")
lInfNormData.show()
// 向量的无穷阶范数即向量中所有值中的最大值
+---+--------------+--------------+
| id| features| normFeatures|
+---+--------------+--------------+
| 0|[1.0,0.5,-1.0]|[1.0,0.5,-1.0]|
| 1| [2.0,1.0,1.0]| [1.0,0.5,0.5]|
| 2|[4.0,10.0,2.0]| [0.4,1.0,0.2]|
+---+--------------+--------------+
4.2 StandardScaler
StandardScaler处理的对象是每一列,也就是每一维特征,将特征标准化为单位标准差或是0均值,或是0均值单位标准差。
作用对象:列
方法公式:(colX-avgValue)/stddev
主要有两个参数可以设置:
withStd: 默认为真。将数据标准化到单位标准差。
withMean: 默认为假。是否变换为0均值。
StandardScaler需要fit数据,获取每一维的均值和标准差,来缩放每一维特征。
import org.apache.spark.ml.feature.StandardScaler
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
// Compute summary statistics by fitting the StandardScaler.
val scalerModel = scaler.fit(dataFrame)
// Normalize each feature to have unit standard deviation.
val scaledData = scalerModel.transform(dataFrame)
scaledData.show
// 将每一列的标准差缩放到1。
+---+--------------+--------------------------------------------+
|id |features |scaledFeatures |
+---+--------------+--------------------------------------------+
|0 |[1.0,0.5,-1.0]|[0.6546536707,0.093521952958,-0.65465367070]|
|1 |[2.0,1.0,1.0] |[1.30930734141,0.18704390591,0.65465367070] |
|2 |[4.0,10.0,2.0]|[2.61861468283,1.8704390591,1.30930734141] |
+---+--------------+--------------------------------------------+
4.3 MinMaxScaler
MinMaxScaler作用同样是每一列,即每一维特征。将每一维特征线性地映射到指定的区间,通常是[0, 1]。
作用对象:列
方法公式:(colX-minValue)/(maxValue-minValue)
有两个参数可以设置:
min: 默认为0。指定区间的下限。
max: 默认为1。指定区间的上限。
import org.apache.spark.ml.feature.MinMaxScaler
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
// Compute summary statistics and generate MinMaxScalerModel
val scalerModel = scaler.fit(dataFrame)
// rescale each feature to range [min, max].
val scaledData = scalerModel.transform(dataFrame)
println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]")
scaledData.select("features", "scaledFeatures").show
// 每维特征线性地映射,最小值映射到0,最大值映射到1。
+--------------+--------------------------------------------+
|features |scaledFeatures |
+--------------+--------------------------------------------+
|[1.0,0.5,-1.0]|[0.0,0.0,0.0] |
|[2.0,1.0,1.0] |[0.33333333333,0.052631578947,0.66666666666]|
|[4.0,10.0,2.0]|[1.0,1.0,1.0] |
+--------------+--------------------------------------------+
4.4 MaxAbsScaler
MaxAbsScaler将每一维的特征变换到[-1, 1]闭区间上,通过除以每一维特征上的最大的绝对值,它不会平移整个分布,也不会破坏原来每一个特征向量的稀疏性。
作用对象:列
方法公式:colX/max(|colValue|)
import org.apache.spark.ml.feature.MaxAbsScaler
val scaler = new MaxAbsScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
// Compute summary statistics and generate MaxAbsScalerModel
val scalerModel = scaler.fit(dataFrame)
// rescale each feature to range [-1, 1]
val scaledData = scalerModel.transform(dataFrame)
scaledData.select("features", "scaledFeatures").show()
// 每一维的绝对值的最大值为[4, 10, 2]
+--------------+----------------+
| features| scaledFeatures|
+--------------+----------------+
|[1.0,0.5,-1.0]|[0.25,0.05,-0.5]|
| [2.0,1.0,1.0]| [0.5,0.1,0.5]|
|[4.0,10.0,2.0]| [1.0,1.0,1.0]|
+--------------+----------------+
5.总结
通过对SparkMllib特征工程中涉及的数值型数据的处理分析,总结如何对机器学习中的样本和特征数据的分析和实践,通过总结分析得到对应结论,希望这部分知识能够对初步学习SparkMllib但是对特征工程,尤其是数值型数据的特征工程理解存在问题的能够起到作用。
推荐了解:
大数据培训课程
python+人工智能课程
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
