
















 AI智能应用开发(Java)
AI智能应用开发(Java) 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


Kafka生产、消费数据的工作流程
更新时间:2021年10月19日13时44分 来源:传智教育 浏览次数:
生产者先从 zookeeper 的 "/brokers/topics/主题名/partitions/分区名/state"节点找到该 partition 的leader.
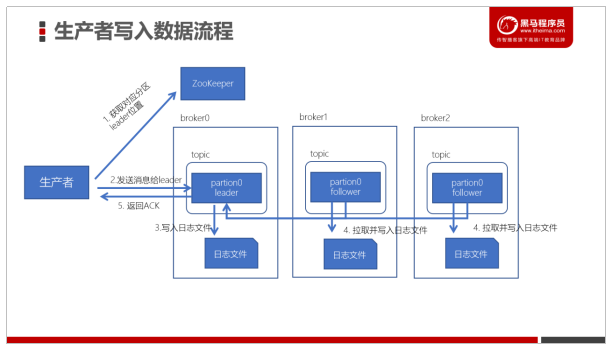
l 生产者在ZK中找到该ID找到对应的broker

l broker进程上的leader将消息写入到本地log中
l follower从leader上拉取消息,写入到本地log,并向leader发送ACK
l leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK。

Kafka数据消费流程
有2种消费模式:
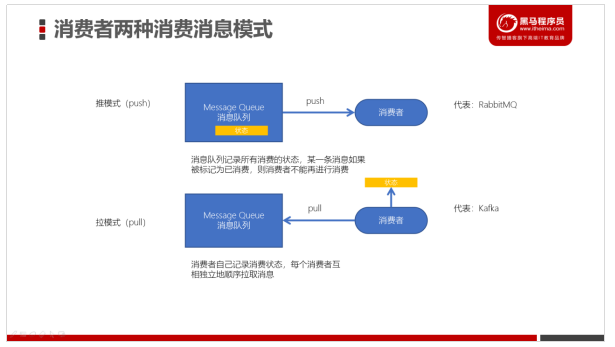
l kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息
l 消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
Kafka消费数据流程
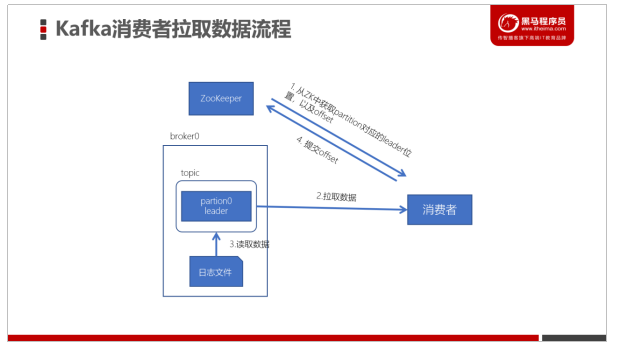
l 每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区
l 获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)
l 找到该分区的leader,拉取数据
l 消费者提交offset
猜你喜欢:最新资讯
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号