
















 AI智能应用开发(Java)
AI智能应用开发(Java) 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


yolo算法:基础概念和Yolo网络结构
更新时间:2022年12月07日11时38分 来源:传智教育 浏览次数:
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别,整个系统如下图所示:

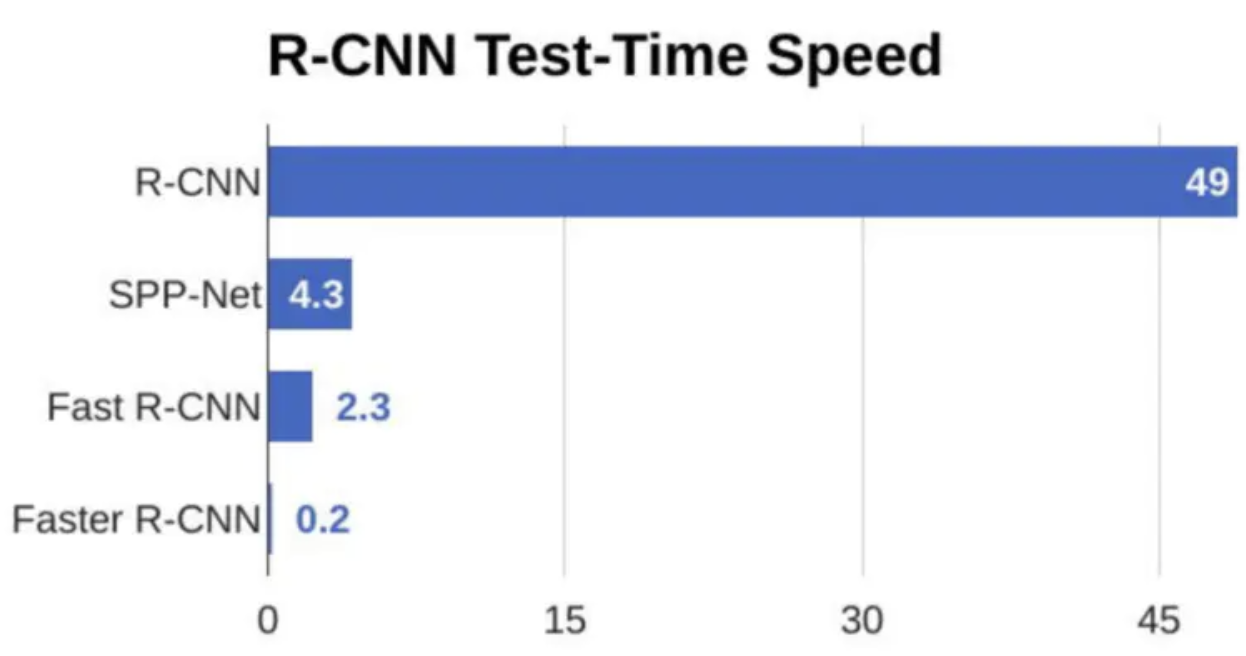
首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快。
Yolo算法
在介绍Yolo算法之前,我们回忆下RCNN模型,RCNN模型提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右,然后对每个候选区进行对象识别,但处理速度较慢。
Yolo意思是You Only Look Once,它并没有真正的去掉候选区域,而是创造性的将候选区和目标分类合二为一,看一眼图片就能知道有哪些对象以及它们的位置。
Yolo模型采用预定义预测区域的方法来完成目标检测,具体而言是将原始图像划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。我们将其理解为98个预测区,很粗略的覆盖了图片的整个区域,就在这98个预测区中进行目标检测。
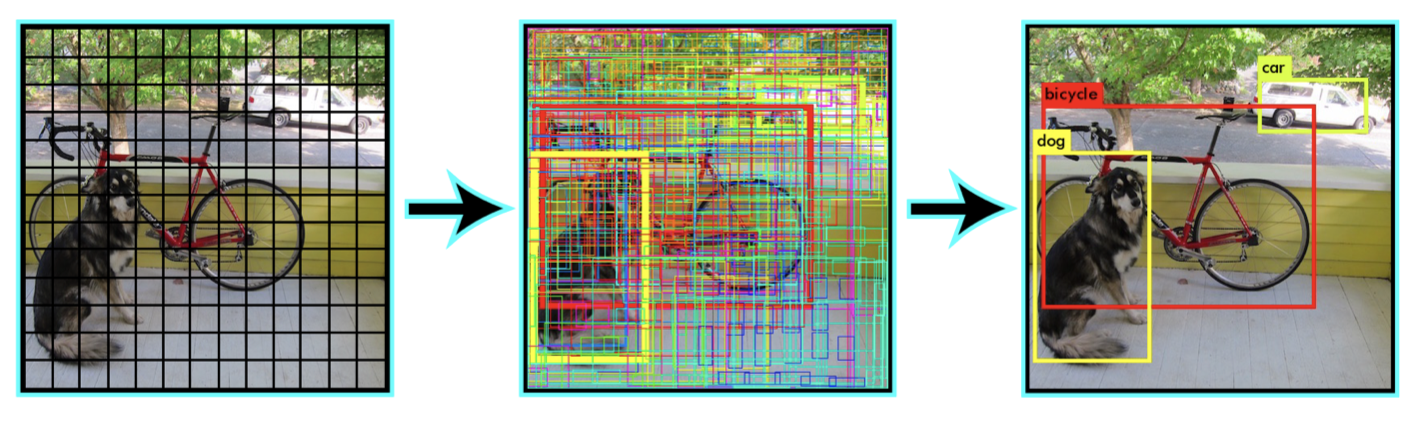
只要得到这98个区域的目标分类和回归结果,再进行NMS就可以得到最终的目标检测结果。那具体要怎样实现呢?
Yolo的网络结构
YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接,从网络结构上看,与前面介绍的CNN分类网络没有本质的区别,最大的差异是输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示:
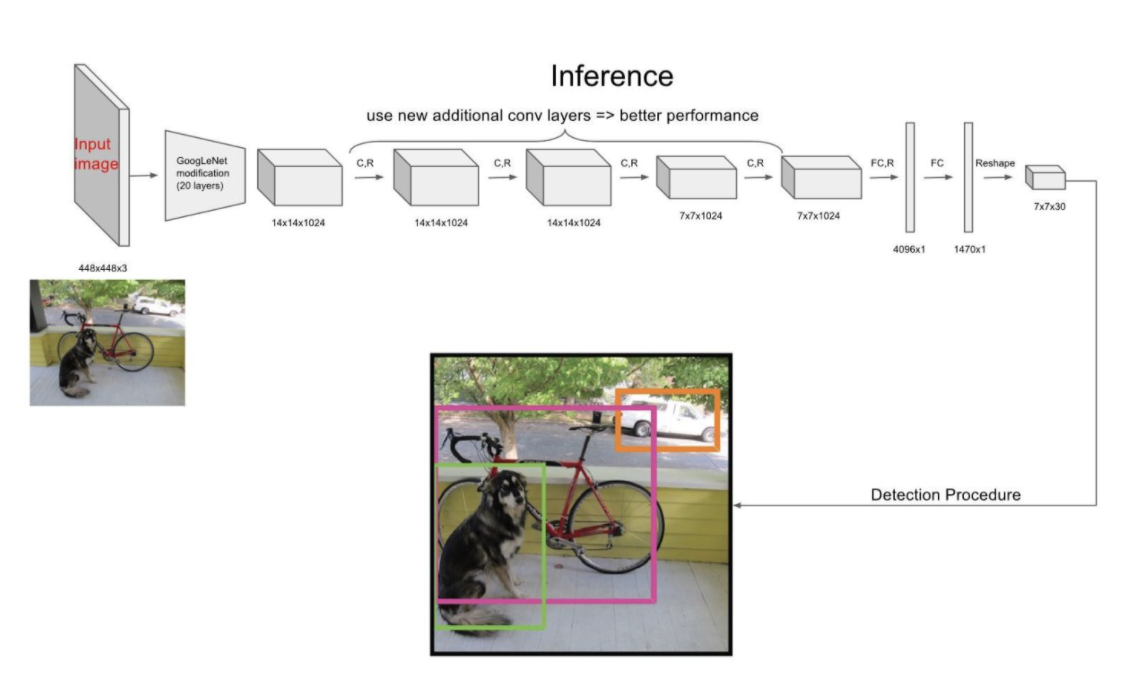
网络结构比较简单,重点是我们要理解网络输入与输出之间的关系。
网络输入
网络的输入是原始图像,唯一的要求是缩放到448x448的大小。主要是因为Yolo的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以Yolo的输入图像的大小固定为448x448。
网络输出
网络的输出就是一个7x7x30 的张量(tensor)。那这个输出结果我们要怎么理解那?
1.7X7网格
根据YOLO的设计,输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。如下图所示,比如输入图像左上角的网格对应到输出张量中左上角的向量。
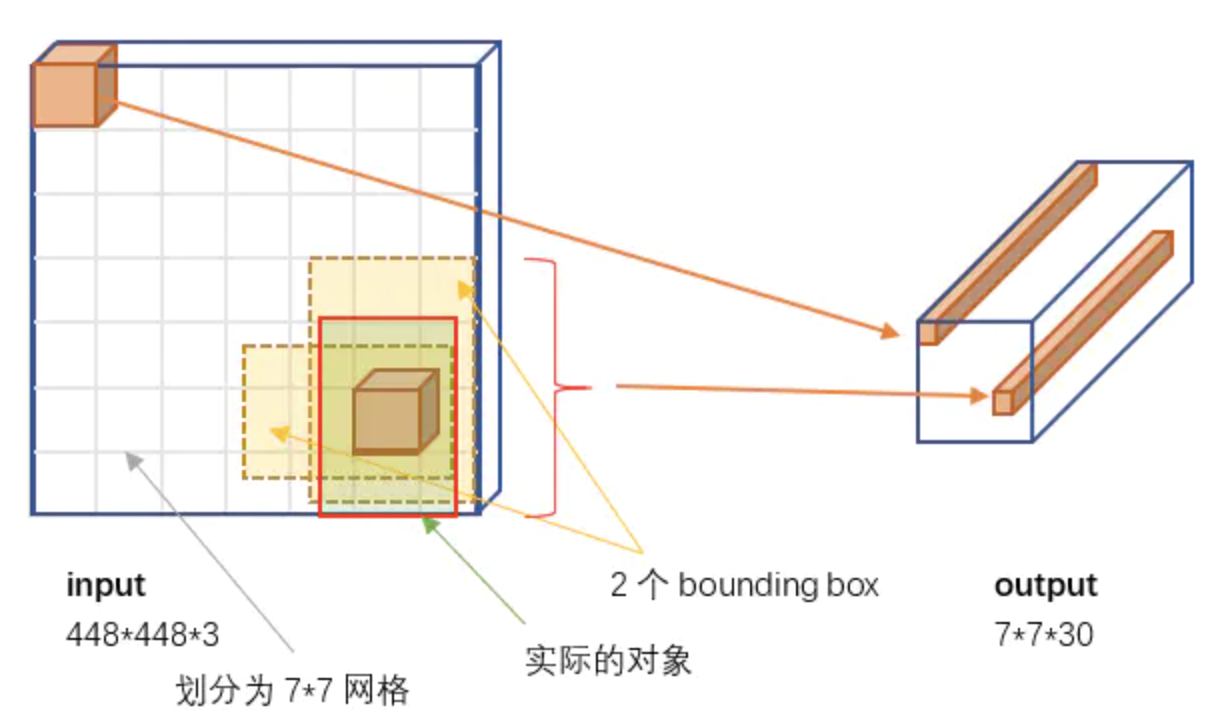
2.30维向量
30维的向量包含:2个bbox的位置和置信度以及该网格属于20个类别的概率。
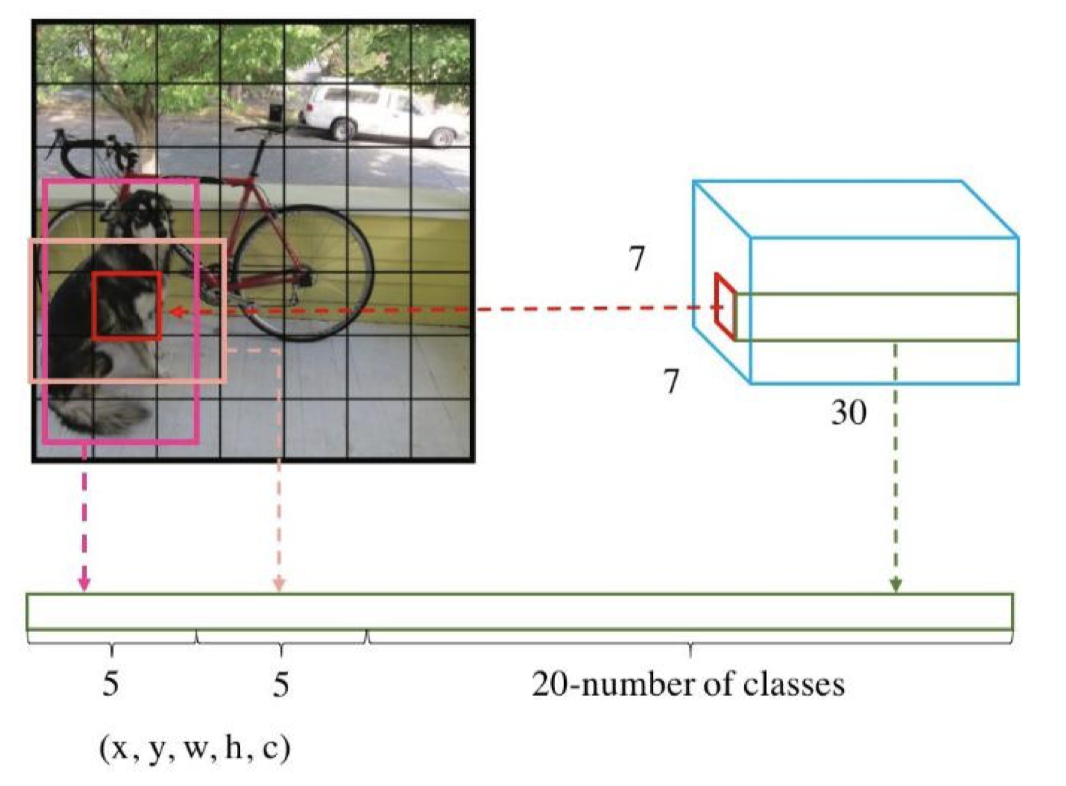
2个bounding box的位置 每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
2个bounding box的置信度 bounding box的置信度 = 该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU,用公式表示就是:
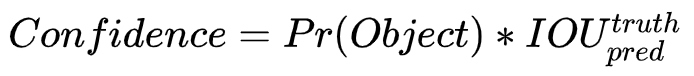
Pr(Object)是bounding box内存在对象的概率
20个对象分类的概率
Yolo支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号