
















 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


Spark3.x中Adaptive Query Execution的自适应查询
更新时间:2022年02月21日18时11分 来源:传智教育 浏览次数:
由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想在Spark3.x版本提供Adaptive Query Execution自适应查询技术通过在”运行时”对查询执行计划进行优化, 允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据统计进行动态优化, 从而提高性能。
Adaptive Query Execution AQE主要提供了三个自适应优化:
- 动态合并 Shuffle Partitions
- 动态调整Join策略
- 动态优化倾斜Join(Skew Joins)
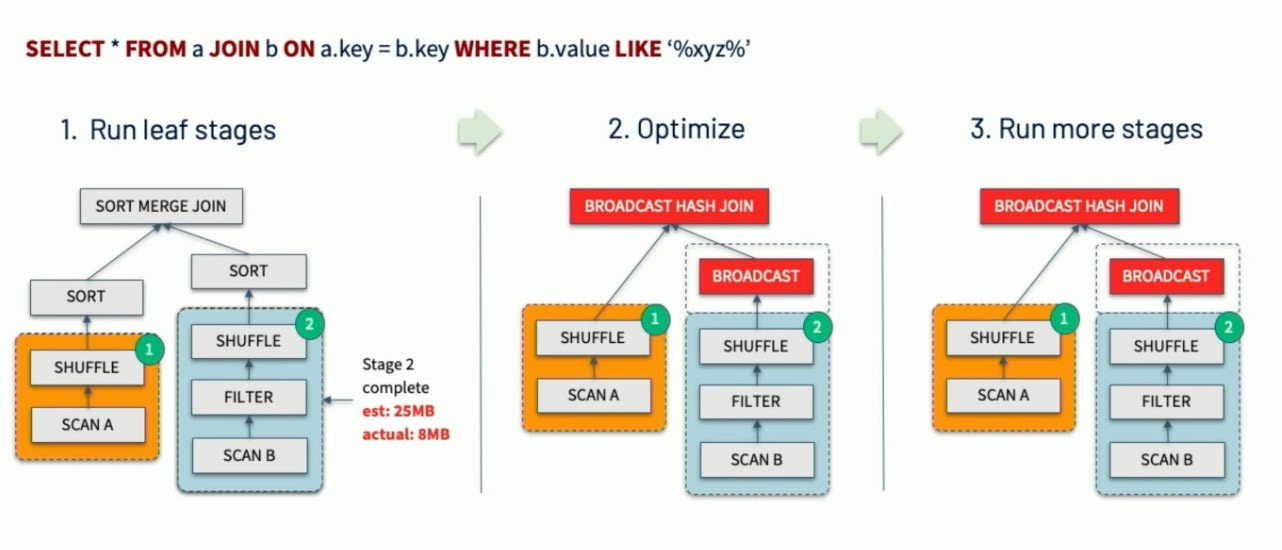
1.动态调整Join策略Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能。
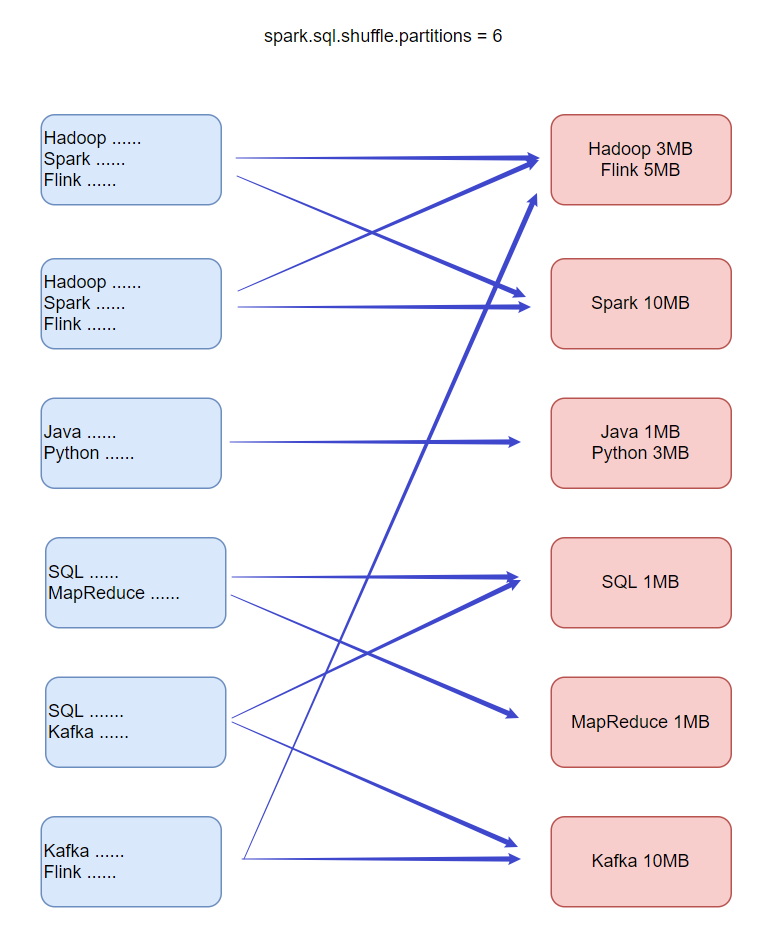
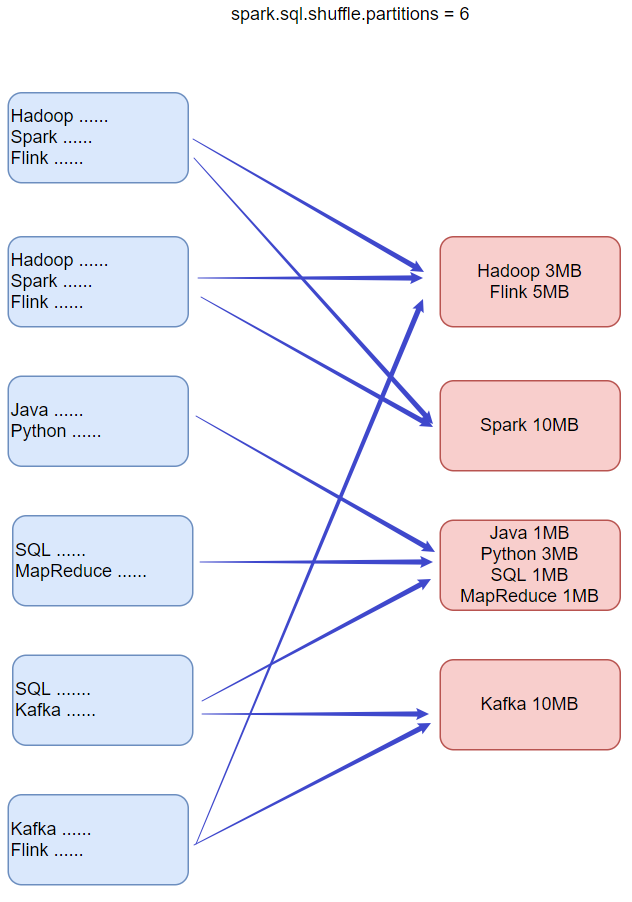
2.动态调整Join策略Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能。
3.动态优化倾斜Join
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
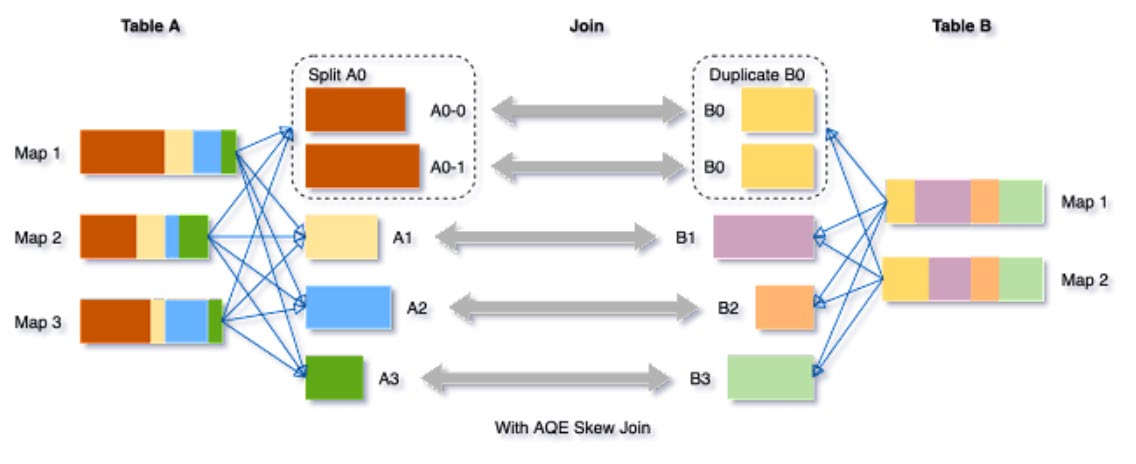
触发条件: 1. 分区大小> spark.sql.adaptive.skewJoin.skewedPartitionFactor (default=10) * "median partition size(中位数分区大小)"
2. 分区大小> spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes (default = 256MB)。
总结:
1. AQE的开启通过: spark.sql.adaptive.enabled 设置为true开启。
2. AQE是自动化优化机制, 无需我们设置复杂的参数调整, 开启AQE符合条件即可自动化应用AQE优化。
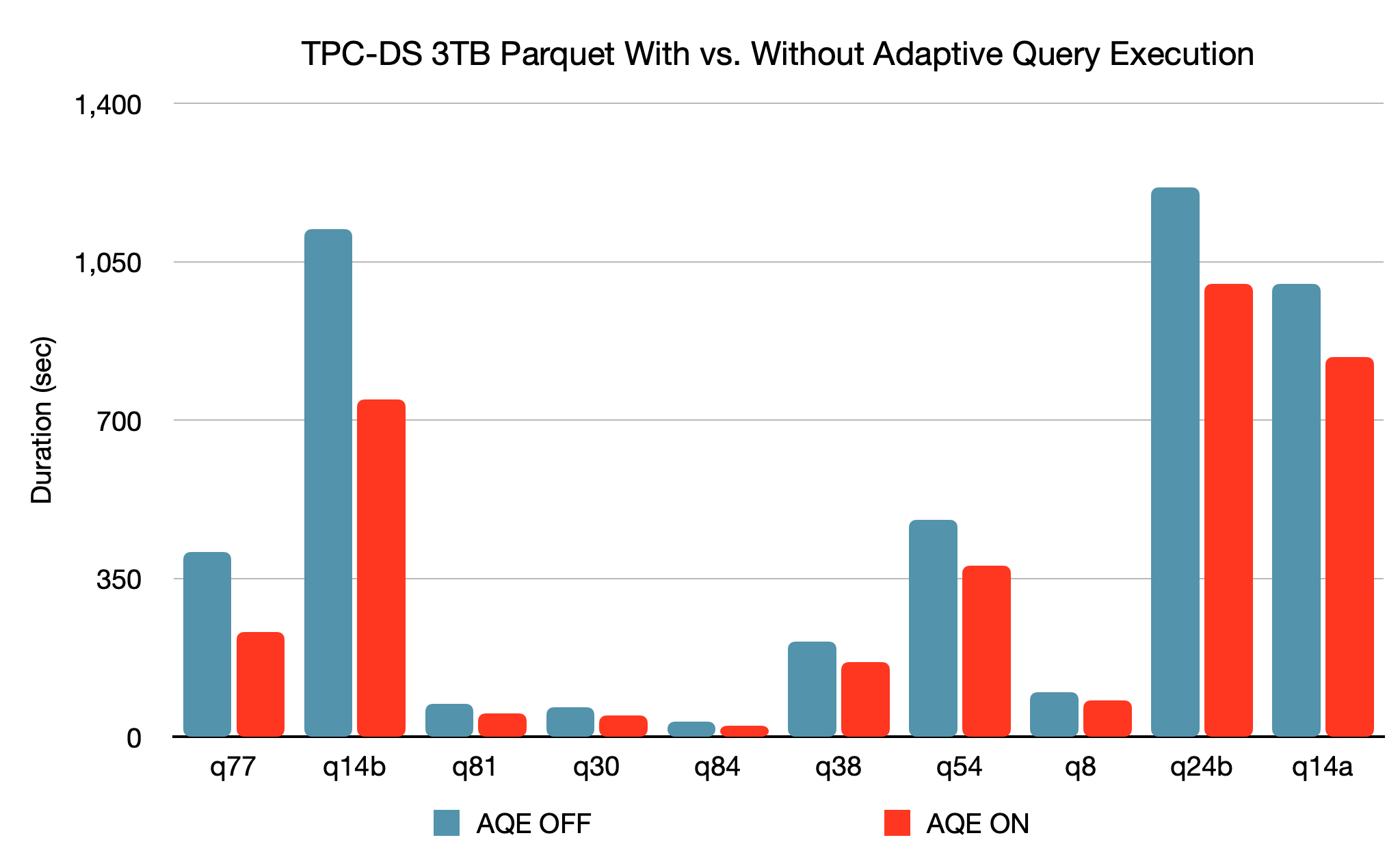
3. AQE带来了极大的SparkSQL性能提升。
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号