
















 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


MapReduce性能调优方法有哪些?
更新时间:2022年03月28日16时46分 来源:传智教育 浏览次数:
使用Hadoop进行大数据运算,当数据量极其大时,那么对MapReduce性能的调优重要性不言而喻,尤其是Shuffle过程中的参数配置对作业的总执行时间影响特别大。下面总结一些和MapReduce相关的性能调优方法,主要从五个方面考虑:数据输入、Map阶段、Reduce阶段、Shuffle阶段和其他调优属性。
1.数据输入
在执行MapReduce任务前,将小文件进行合并,大量的小文件会产生大量的map任务,增大map任务装载的次数,而任务的装载比较耗时,从而导致MapReduce运行速度较慢。因此我们采用CombineTextInputFormat来作为输入,解决输入端大量的小文件场景。
2.Map阶段
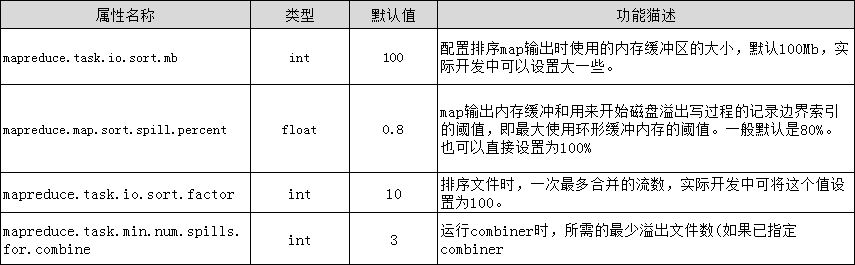
(1)减少溢写(spill)次数:通过调整io.sort.mb及sort.spill.percent参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘IO。
(2)减少合并(merge)次数:通过调整io.sort.factor参数,增大merge的文件数目,减少merge的次数,从而缩短mr处理时间。
(3)在map之后,不影响业务逻辑前提下,先进行combine处理,减少I/O。我们在上面提到的那些属性参数,都是位于mapred-default.xml文件中,这些属性参数的调优方式如表4-1所示。
表4-1Map阶段调优属性
3.Reduce阶段
(1)合理设置map和reduce数:两个都不能设置太少,也不能设置太多。太少,会导致task等待,延长处理时间;太多,会导致map、reduce任务间竞争资源,造成处理超时等错误。
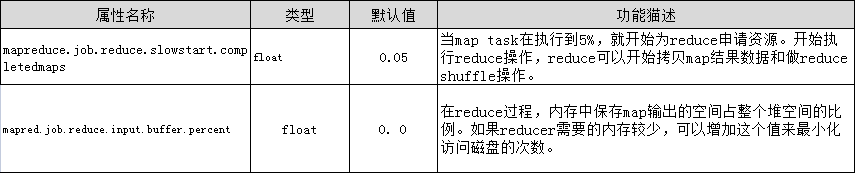
(2)设置map、reduce共存:调整slowstart.completedmaps参数,使map运行到一定程度后,reduce也开始运行,减少reduce的等待时间。
(3)规避使用reduce:因为reduce在用于连接数据集的时候将会产生大量的网络消耗。通过将MapReduce参数setNumReduceTasks设置为0来创建一个只有map的作业。
(4)合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销。这样一来,设置buffer需要内存,读取数据需要内存,reduce计算也要内存,所以要根据作业的运行情况进行调整。
我们在上面提到的属性参数,都是位于mapred-default.xml文件中,这些属性参数的调优方式如表4-2所示。
表4-2Reduce阶段的调优属性
4.Shuffle阶段
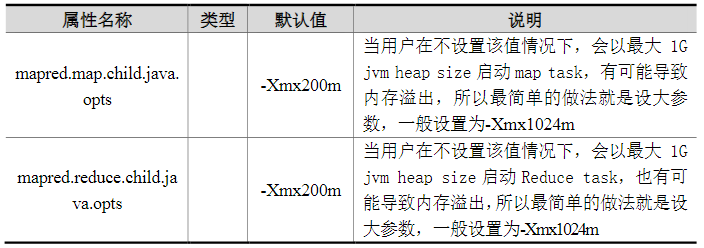
Shuffle阶段的调优就是给Shuffle过程尽量多地提供内存空间,以防止出现内存溢出现象,可以由参数mapred.child.java.opts来设置,任务节点上的内存大小应尽量大。
我们在上面提到的属性参数,都是位于mapred-site.xml文件中,这些属性参数的调优方式如表4-3所示。
表4-3shuffle阶段的调优属性
5.其他调优属性
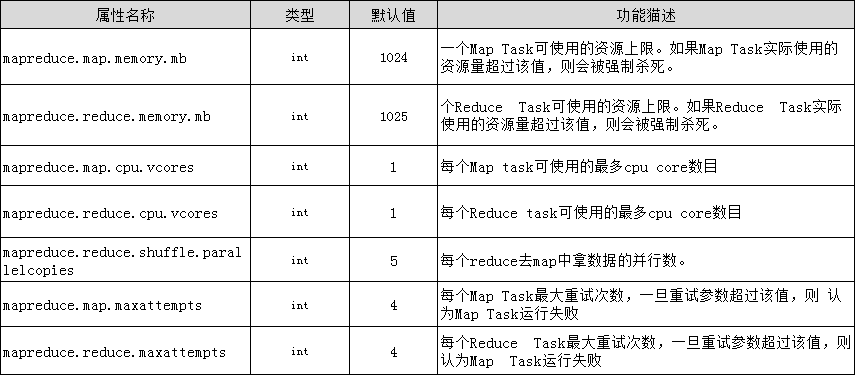
除此之外,MapReduce还有一些基本的资源属性的配置,这些配置的相关参数都位于mapred-default.xml文件中,我们可以合理配置这些属性提高MapReduce性能,表4-4列举了部分调优属性。
表4-4MapReduce资源调优属性
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号